

Em um post anterior eu descrevi como é o início do processo de tomada de decisão com dados, e da necessidade de ter dados confiáveis. Se fosse organizar um livro, talvez o artigo abaixo devesse ser um capítulo anterior, pois minha ideia é explicar o fluxo macro do processo de análise de dados.
O propósito da análise de analisar dados é transformar perguntas em respostas. Uma pergunta pode ser desde uma provocação, uma curiosidade científica ou uma necessidade de negócio. A resposta, da mesma maneira, pode variar desde uma declaração curta (mas embasada) até um produto físico ou virtual que responde ao questionamento inicial.
Podemos enxergar o trabalho analítico e de ciência de dados como um ciclo de ações que após algumas iterações nos dará um resultado. A figura abaixo demonstra esse fluxo de trabalho
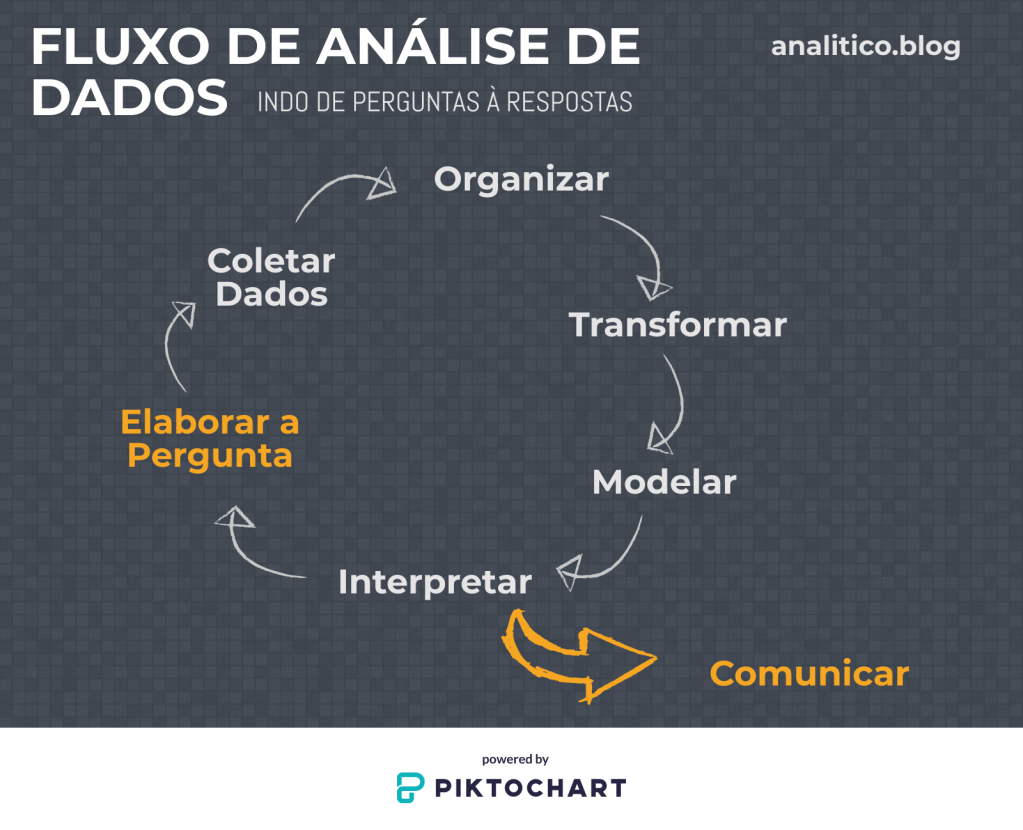
Começamos, primeiramente, com perguntas do tipo “Por que….?”, “E se….?”, “Como …. ?”, que podem vir tanto de nossa curiosidade como de nossa necessidade. E essas perguntas podem ser vagas ou muito abertas, mas isso não as torna menos importantes.
Como analistas – não no sentido de nome de cargo, mas como indivíduo que irá fazer uma análise – temos que buscar respostas para essas perguntas. E isso pode incluir o detalhamento, refinamento ou releitura completa da pergunta original.
Com uma pergunta na cabeça, vamos à coleta de dados. Coletar dados também pode variar desde o aperto de um botão até um projeto complexo em si. A demanda tão grande por Engenheiros de Dados atualmente é parte desse contexto onde é necessário extrair dados e deixá-los acessíveis para as análises.
Se dados são o novo petróleo, vamos imaginar que primeiramente precisamos extrair o petróleo e refiná-lo para depois vendermos gasolina. Coletar dados, seja com pesquisa de campo, medições, formulários ou extrações de um banco, é dos primeiros e fundamentais passos para uma boa análise.
Mas dados brutos raramente podem ser usando sem um refinamento ou transformação prévia. É necessário organizá-los, filtrá-los, cruzá-los com outros dados, transformá-los para enfim poder utilizá-los.
O resultado desse processo de refinamento é uma base de dados organizada e pronta para a análise. Os dados aqui estão prontos para o que o analista quiser fazer: visualizar, testar hipóteses, criar modelos estatísticos, previsões, etc.
Normalmente você não terá sorte de ter todas as respostas com a base de dados que você montou (ou montaram para você). Você precisará de mais dados – ou talvez menos, transformações diferentes, categorizações diferentes, formatos diferentes. Assim você trabalha para ter uma nova base organizada para reiniciar sua análise.
A interpretação dos resultados é essencial para concluir a análise, ou fazer novas perguntas que reiniciarão o ciclo, até que você esteja satisfeito com os resultados.
Com o resultado completo, é hora de comunicar. Essa etapa, como comentei, também pode variar significativamente de tamanho. Pode ser um relatório ou pode ser um projeto em si, tornando sua análise e seu modelo de machine learning um produto.
Essa estrutura básica é o que forma hoje um ciclo de um projeto de Ciência de Dados, e que permeia tanto a abordagem científica de descoberta e teste de hipóteses quanto a aplicação e comunicação e ação prática que a realidade necessita.

